
Analisis Faktor
- Paham Statistika
- Feb 2, 2022
- 7 min read

Updated: Feb 4, 2022
Metode ekstraksi variabel seperti halnya PCA yang digunakan dalam menyederhanakan dan mempelajari variabel tersembunyi dalam data. Blog ini akan membahas informasi dasar mengenai analisis faktor. (Ditulis oleh : HN Rizka, Februari 2022).
"An approximate answer to the right problem is worth a good deal more than an exact answer to an approximate problem." - John Tukey
Definisi dari analisis faktor yang secara umum disetujui merupakan metode dalam menganalisis variabel "tersembunyi" dalam data yang dikenal dengan nama "faktor". Metode ini terinspirasi oleh teknik ekstraksi variabel menggunakan statistik. Fokus dari analisis faktor adalah menjelaskan "persebaran antar variabel" yang biasa direpresentasikan oleh kovariansi. Sebagai pengingat, persebaran dalam satu variabel dapat diukur dengan variansi, sedangkan kovariansi merupakan perumuman dari variansi sedemikian hasilnya memberikan ukuran persebaran pada dua variabel. Sebagai contoh adalah pengukuran kecerdasan umum menggunakan beberapa indikator seperti kemampuan linguistik (tulisan), pemikiran kritis, dan kinestetik (tubuh).

Dalam menganalisis faktor, logika yang mirip seperti PCA digunakan yaitu prosedur ekstraksi informasi. Perbedaan utama dari analisis faktor dengan PCA adalah fokus dari analisis faktor yang lebih kepada mempelajari variabel tersembunyi atau faktor itu sendiri. Selain itu, dalam analisis faktor, kita tidak "menciptakan" variabel baru seperti PCA, namun mengasumsikan bahwa terdapat variabel yang membentuk variabel-variabel yang diukur dalam data.

Dari gambar diatas, arah panah merepresentasikan arah pembentukan. Implikasinya, sesuai dengan yang telah disebutkan : PCA membentuk variabel baru yang berupa komponen, sedangkan analisis faktor memulai dengan asumsi bahwa terdapat variabel yang membentuk data.
Dari pembedaan diatas, dapat dikatakan bahwa analisis faktor memiliki fokus dalam mempelajari hal-hal "tersembunyi" dalam data. Untuk memberikan gambaran mengenai apa yang dimaksud dengan mempelajari hal tersembunyi tersebut, misalkan anda ingin mengukur tingkat kecemasan seseorang. Tentunya anda tidak dapat serta merta langsung mendapatkan ukuran tersebut. Dalam psikologi, untuk mengukur hal tersebut dapat dilakukan tes kuesioner dengan pertanyaan-pertanyaan seperti berikut :
Saya sering merasa sedih di malam hari
Saya tidak dapat mengendalikan rasa takut dan kekhawatiran dengan suatu hal
Saya sulit merasa santai di hari libur
dan seterusnya. Kuesioner semacam ini berguna dalam mengukur tidak hanya tingkat kecemasan namun juga perilaku atau psikologi manusia secara umum. Selanjutnya, dengan adanya kuesioner tersebut, selanjutnya tentu diperlukan suatu metode dalam menganalisis bagaimana hubungan pertanyaan-pertanyaan tersebut dengan tingkat kecemasan seseorang. Hal seperti inilah yang menjadi perhatian dalam analisis faktor. Dengan mengasumsikan bahwa tingkat kecemasan merupakan latar belakang dalam perilaku-perilaku yang bersesuaian dengan kuesioner, selanjutnya dapat dianalisis konstruksi antara pertanyaan dalam kuesioner dengan tingkat kecemasan seseorang. Analisis konstruksi tersebut juga merupakan poin penting dalam analisis faktor.
Contoh lain penggunaan analisis faktor juga ada pada bidang sosial-ekonomi yaitu seperti status sosial seseorang. Secara garis besar, penulis ingin mengatakan bahwa analisis faktor lebih berfokus pada mempelajari ukuran yang tidak memiliki alat ukur baku melalui pengukuran variabel-variabel yang dicurigai dipengaruhi ukuran tersebut. Seperti contoh sebelumnya yaitu kecemasan, kecerdasan, status sosial, dan sebagainya.
Dari perbedaan yang telah disebutkan, prosedur dalam analisis aktor secara garis besar adalah sama. Karena perannya sebagai metode ekstraksi informasi dari data, analisis faktor mempelajari faktor tersembunyi dengan melakukan standardisasi data kemudian membuat matriks korelasi yang dihitung nilai eigen dan vektor eigennya. Hasil dari analisis fakor juga terurut berdasarkan faktor yang mengandung "informasi" terbesar. Untuk meringkas perbedaan teknis pada analisis faktor dengan PCA, dapat direpresentasikan sebagai berikut :
Analisis faktor menganggap bahwa variabel dalam data merupaka kombinasi linear dari variabel tersembunyi atau faktor yang ingin dipelajari. PCA bekerja dengan mengkombinasikan variabel dalam data untuk mebangun variabel baru yaitu komponen.
PCA berfokus pada "total variansi dijelaskan" sedangkan analisis faktor mempertimbangkan keseluruhan elemen dalam matriks kovariansi. Sebagai pengingat, variansi dalam data hanya menjelaskan persebaran untuk variabel tertentu sedangkan kovariansi merupakan representasi persebaran antara dua variabel.
Analisis faktor memiliki solusi yang "tidak unik". Hal ini disebabkan oleh konsep rotasi pada faktor yang bertujuan dalam menyederhanakan interpretasi dari faktor itu sendiri.
Perbedaan detail teknis tentunya ada, namun penulis mengurungkan untuk membahas detail tersebut dan langsung ke contoh penggunaan analisis faktor. Bagi pembaca yang ingin mendalami lebih lanjut mengenai teori dalam analisis faktor dapat membaca salah satu rujukan penulis : Matematika dalam analisis faktor
Analisis Faktor Pada data Klien
Untuk memberikan contoh pada penerapan analisis faktor, kita kembali menggunakan data klien kartu kredit bank. Untuk informasi mengenai data dapat anda lihat ada post PCA .
Preliminary Analysis
Dalam menganalisis data menggunakan analisis faktor, pertama perlu dilakukan diagnosis kecocokan data untuk dianalisis menggunakan analisis faktor. Untuk melakukan diagnosis ini, pertama daapt dimulai dari mengidentifikasi hubungan antar variabel dalam data. Tentunya dalam contoh kali ini dapat dipastikan bahwa setiap variabel dicurigai kuat memiliki hubungan satu dengan lainnya. Berdasarkan hasil PCA sebelumnya, komponen utama yang dihasilkan menyatakan bahwa dimensi pertama didominasi oleh Bill_ atau total tagihan. Walau ini tidak bisa dijadikan dasar untuk menyatakan faktor tersembunyi tersebut membentuk variabel-variabel Bill_, kita tahu bahwa informasi dalam Bill_ mendominasi data dan berkontribusi kuat dalam satu dimensi pada PCA. Prosedur ini merupakan analisis prior information (informasi awal) menggunakan intuisi penulis. Cara lain yang lebih populer digunakan dan tentunya lebih aplikatif (karena tidak semua orang memulai analisis data dengan PCA) adalah dengan matriks korelasi data.

Dari matriks korelasi diatas, terlihat bahwa setengah dari seluruh variabel dalam data memiliki korelasi yang sangat tinggi. Keadaan data yang memiliki korelasi antar variabel yang tinggi seperti ini sangat cocok dianalisis dengan analisis faktor. Tentu ambang batas mengenai seberapa besar korelasi antar variabel dapat diuji menggunakan analisis korelasi lebih lanjut seperti contoh pada video berikut (oleh Datatab) :
Selanjutnya kita akan melihat ukuran factorability. Factorability memberikan gambaran mengenai ada/tidaknya beberapa korelasi di antara variabel-variabel sehingga faktor-faktor yang koheren dapat diidentifikasi. Ukuran ini merupakan ukuran yang lebih dapat diandalkan dalam melihat hubungan antar variabel yang berhubungan sedemikian peneliti mampu mengambil keputusan mengenai valid/tidaknya penggunaan analisis faktor pada data. Terkait ambang penerimaan, Kaiser (1974) memberikan interval sebagai berikut :

Sebagai rule-of-thumb penggunaannya adalah nilai 0.8-1 mengindikasikan sampling sudah memadai, kurang dari 0.6 (beberapa penulis juga memberikan batas 0.5) menunjukkan perlunya perbaikan/penyesuaian jika analisis faktor ingin tetap dilanjutkan, sedangkan nilai yang terlalu kecil dan mendekati 0 akan menemui masalah dalam penerapan analisis faktor. Penlis lebih cenderung menggunakan batas 0.5, hal ini karena error dalam data survei sangatlah sering terjadi dan terkadang karena pemahaman akan kuesioner tersebut rendah atau karena objek survei itu sendiri yang sulit diukur karena alasan tertentu. Sebagai contoh adalah ketika melakukan analisis terkait kebiasaan seseorang. Pertanyaan-pertanyaan pada topik ini sangatlah rawan untuk menyentuh privasi seseorang, sehingga jika peneliti tidak berhati-hati dalam mengkonsturksi kuesioner, responden akan cenderung tidak menjawab sesuai keadaannya.
Hasil penghitungan ukuran kecukupan sampling yang didapatkan adalah sebagai berikut :

Berdasarkan ukuran kecukupan sampling/MSA diatas terdapat beberapa variabel yang kurang dari ambang batas penerimaan 0.5. Untuk kasus ini, penulis memutuskan untuk tetap mempertahankan seluruh variabel. Alasan utamanya adalah secara keseluruhan, kriteria KMO sudah mencapai batas yang cukup baik yaitu 0.74. Selain itu, tujuan utama dalam analisis faktor masih dapat tercapai dengan keadaan data klien tersebut.
Metode serupa untuk menentukan apakah hasil analis faktor pada data kita berguna atau tidak adalah dengan uji bartlett. Sebagai tambahan, penghitungan determinan matriks korelasi data dihitung untuk menentukan apakah terdapat masalah multikolinearitas dalam data. Didaptkan nilai determinan matriks korelasi sangatlah kecil yaitu 0.0000016 yang mana berdasarkan sumber seperti Teori dan Aplikasi EFA nilai ini dibawah ambang batas penerimaan yaitu 0.00001. Sehingga perlu adanya penyesuaian pada data. Penulis memutuskan untuk menyesuaikan berdasarkan deskripsi data klien yaitu membuang variabel pengamatan Bill_AMT6 dan Pay_AMT6 yang merupakan variabel pengamatan "tertua". Hasilnya didapatkan nilai determinan 0.0000266. Sehingga setelah dilakukan preliminary analysis atau analisis pendahuluan untuk analisis faktor didapatkan data yang akan dianalisis adalah seperti contoh berikut :

Penerapan Analisis Faktor
Setelah memastikan data siap, analisis faktor dapat langsung diterapkan. Untuk memberikan konteks mengenai hasil yang didapatkan nantinya, berikut adalah beberapa istilah dalam analisis faktor :
Variansi umum : tingkat variansi yang dibagi diantara satu himpunan variabel. Variabel-variabel yang sangat berkorelasi akan berbagi tingkat variansi yang tinggi. Salah satu bentuknya adalah communality yaitu variansi umum yang bernilai antara 0 dan 1. Nilai yang mendekati 1 menunjukkan bahwa faktor yang diekstrak menjelaskan lebih banyak variansi dari item individual.
Variansi unik : bagian dari variansi keseluruhan data yang selain dari variansi umum. Variansi ini dibagi menjadi 2 yaitu variansi spesifik variabel/item dan variansi error. Sesuai dengan namanya masing-masing, variansi spesifik variabel adalah variansi dari tiap variabel sedangkan variansi error berasal dari sisa variansi yang tidak dijelaskan oleh variansi spesifik ataupun umum.
Untuk lebih dapat membayangkan kedua jenis variansi diatas anda dapat melihat gambar berikut :
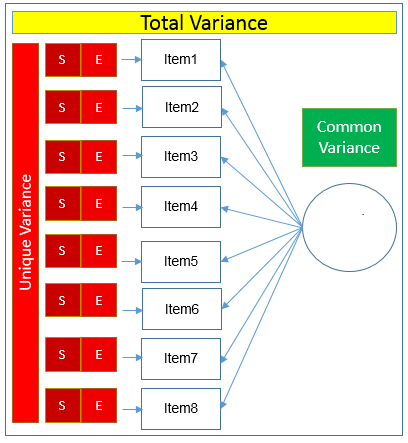

Terkait prosedur dalam menerapkan analisis faktor, terdapat 2 langkah utama : ekstraksi dan rotasi. Prosedur ekstraksi dapat dilakukan dengan PCA. Berikut adalah penerapan PCA untuk data sebelumnya :

dari hasil diatas, kita dapatkan loading dari setiap variabel pada data dengan komponen yang terbentuk. Contoh Bill_AMT1 memiliki korelasi 0.4156 dengan komponen pertama dan -0.203 dengan komponen kedua dan seterusnya. Selain itu, kuadrat dari setiap loading tersebut merupakan proporsi variansi yang dijelaskan komponen yang berkorespondensi. Contoh pada Bill_AMT1 maka sebesar : 0.4156*0.4156 = 0.1727 dari variansinya dijelaskan oleh komponen pertama. Untuk masing-masing variabel, jika jumlahan kuadrat seperti ini dijumlahkan, nilainya akan sama dengan 1. Inilah yang dimaksud sebagai communality dan untuk PCA nilai ini untuk setiap variabelnya akan sama dengan total variansi. Hal ini dapat direpresentasikan dengan
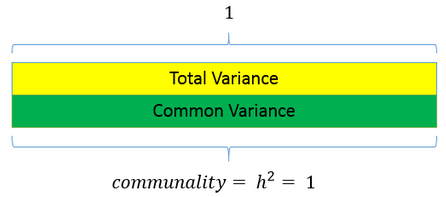
Mempartisi total variansi diatas memberikan gambaran mengenai perbedaan teknis ekstraksi PCA dengan analisis faktor. Dalam prosedur ekstraksi dengan common factor, diasumsikan bahwa total variansi dapat dipartisi menjadi variansi umum dan unik. Biasanya lebih masuk akal untuk berasumsi bahwa anda belum mengukur apa yang ingin anda ukur secara sempurna. Maka dari itu, kita mengasumsikan adanya variabel tersembunyi yang variansinya merupakan variansi umum.
Dengan dasar hasil PCA sebelumnya, anggap terdapat 2 faktor yang mengkonstruksi data klien. Didapatkan hasil berikut :

Didapatkan bahwa dengan menganggap bahwa terdapat 2 faktor yang membelakangi data klien, total variansi yang dijelaskan dari data mencapai lebih dari 50%. Tentu hasil ini dapat tidak anda gunakan. Misalnya karena anda ingin banyaknya faktor selain 2. Terkait penentuan banyaknya faktor ini, terdapat beberapa cara. Salah satunya adalah dengan analisis paralel berikut :

Dari plot diatas, anda dapat menggunakan saran untuk membangun PCA dengan 2 komponen dan analisis faktor dengan 5 faktor. Selanjutnya untuk memberikan gambaran hubungan faktor dengan masing-masing variabel dapat dilihat melalui diagram berikut :

Dari hasil diatas, terlihat bahwa faktor yang membelakangi masing-masing variabel cukup masuk akal. Faktor 1 merupakan faktor yang melatarbelakangi nilai tagihan kredit (Bill_) seseorang. Sedangkan faktor 2 melatarbelakangi jumlah pembayaran kredit (Pay_AMT) seseorang.
Hasil dari analisis faktor ini dapat kemudian digunakan untuk membangun model lain seperti halnya hasil PCA. Penulis mengurungkan niat untuk membahas prosedur ini namun bagi pembaca yang tertarik untuk mempelajari lebih lanjut, dapat mereplikasi prosedur dari awal analisis faktor ini dengan software R : analisis faktor .
Comments